Bug #3300
closedzotero translator treats single article as folder
Added by Ben Miller almost 12 years ago. Updated over 9 years ago.
0%
Description
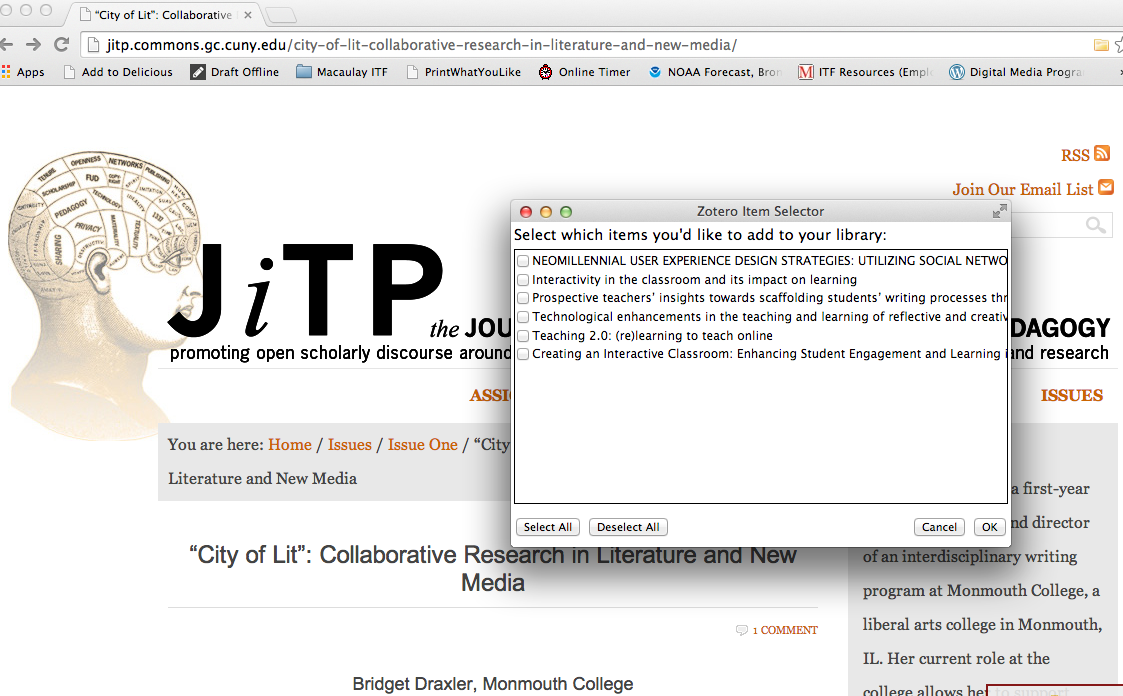
As seen, e.g., at http://jitp.commons.gc.cuny.edu/city-of-lit-collaborative-research-in-literature-and-new-media/ and in the attached image, some articles in the Commons-hosted Journal of Interactive Technology and Pedagogy trigger a Zotero translator (scraper) as if one-click citation were enabled; however, the translator is treating that page as a table of contents, or list of search results, rather than as an individual item. The translator involved appears to be based on DOI.
This seems to be true for all articles in Issue One. Articles in later issues do not trigger Zotero at all, presumably because DOIs were not provided for those entries.
Because the articles on JITP are posts, I assume a similar problem would also happen anywhere that a Commons post was assigned a DOI.
This is happening in Chrome 35.0.1916.153 on MacOS 10.7.5.
Files
{kind=link}
Related issues
Updated by Ben Miller almost 12 years ago
- File Screen Shot of incorrect Zotero folder icon and interface 2014-07-09 at 5.00.48 PM.png Screen Shot of incorrect Zotero folder icon and interface 2014-07-09 at 5.00.48 PM.png added
Oops, forgot the image. Here it is.
Updated by Matt Gold almost 12 years ago
- Category name set to WordPress (misc)
- Status changed from New to Assigned
- Assignee set to Boone Gorges
Updated by Boone Gorges almost 12 years ago
- Assignee changed from Boone Gorges to Daniel Jones
Dan, can I ask you to do a bit of detective work here? You'll need to install the Zotero plugin for your browser: https://www.zotero.org/download/ and do some research into how Zotero decides how to parse a page. I bet Zotero has a guide for making your web resources Zotero-friendly, and it's likely that the JITP theme is doing something wrong. Let me know if you can pick up on anything.
Updated by Daniel Jones almost 12 years ago
It looks like reason the Zotero translator is parsing the page as a folder and not a single item is that in the bibliography some of the entries have DOIs included - my bet is that Zotero interprets any page with multiple DOIs as a collection. I don't think it's reading anything about the article itself, just pulling in the entries in the bibliography that have DOIs. So I don't think the theme is doing anything wrong or being un-friendly to Zotero, just that including more than one DOI in the content of the page means it'll parse it as a collection of documents. I've tested pages with only one DOI in the content and it parses them as a single document. Sorry if all of that is obvious and I was supposed to look for something else.
I guess there might be a way for us to do a check for DOIs in the content of an article and add some markup that'll disrupt the translator (the code for which you can find here: https://github.com/zotero/translators/blob/master/DOI.js) somehow. What do you all think?
Updated by Boone Gorges almost 12 years ago
Thanks for researching this, Dan. Your analysis sounds right to me.
I guess there might be a way for us to do a check for DOIs in the content of an article and add some markup that'll disrupt the translator
Exactly what do you have in mind? I'm curious both about how it'd work technically, and about how we'd implement it from a user's point of view - presumably we'd want this jamming to happen only on pages that were manually marked as bibliographies.
Updated by Ben Miller almost 12 years ago
I don't have privileges to check whether JITP's live site (http://jitp.commons.gc.cuny.edu) is using the COinS Metadata Exposer plugin; I just noticed that our staging site (http://jitpstaging.commons.gc.cuny.edu) isn't. But if we use that plugin to expose the page as a citable object, my understanding is that we would then just need to ensure that the page triggers Zotero's COinS translator instead of the DOI-in-page-text translator that's currently coming up. It's possible this would happen by default; I never got far enough in my Zotero-fu that I could confidently state how priority is established among matching translators.
The place to start digging is probably here (but again, it quickly goes over my head, sorry): http://www.zotero.org/support/dev/exposing_metadata
Updated by Daniel Jones almost 12 years ago
Boone - I don't think this is really a viable solution, but I wanted to see if I could figure something out. Looking at the regex used by the JS parser, it uses \b special character to detect a word boundary in the regex it uses to find DOIs. If we wrote our own JS function that ran before Zotero's (not 100% sure how to make sure of that though. I'd bet Zotero doesn't kick in until after the DOM is totally loaded - I wonder how to make sure our function is in front of it in line) we could set it to look for DOIs (based on the regex Zotero uses) that are adjacent to non-word characters (the ones in the JITP bibliographies are set up like doi:[the DOI itself]) and change that character (in this example, the ':') to an underscore, which is a word character for JS regex so it would trick the JS parser, or we could get rid of the character entirely and just smush the number up against 'doi' which would also do the trick. Then we could give users a way to mark their post as including DOIs they don't want parsed. Maybe even a shortcode with one argument who's callback just output our javascript internally to the page, or I think we could enqueue a JS file with our find-and-replace function in the callback.
Doesn't seem like it'd be totally worth all the trouble, and who knows when the Zotero JS parser might change and the plugin wouldn't work anymore. Also this doesn't take into account other browser plugins that might also look for DOIs and would potentially have different ways of parsing that our find-and-replace wouldn't fool, like if they didn't rely on a word boundary and just looked for the internal DOI regex. Nor does it allow for keeping some DOIs parse-able while hiding others (I guess we could implement this with a shortcode that put spans with a specific class around individual DOIs that we could use with JS to do our finding and replacing). The other issue is that by no longer confirming that the DOIs are next to a word boundary, we introduce a very small risk of a false positive. I doubt many other strings are set up like DOIs internally though, so that seems unlikely. So I don't think it's a perfect approach but it seems like theoretically it could work as things are now, at least for Zotero. I hope I'm not missing anything embarrassing and obvious about this though. Learned a lot about JS regex in the process!
On Ben's question - before trying to look up how priority is established, is there a way to see what happens when we expose the metadata on the page to Zotero? Is JITP already using the COinS plugin and do the relevant pages include metadata to expose? I don't currently have the JITP site on my local install - should we try to get that to me so I can mess around with it?
Updated by Boone Gorges almost 12 years ago
Dan - Thanks very much for doing this research. The technique you sounds like sounds like it might work, but as you suggest, it's pretty hackish and not really viable moving forward.
I think we might want to send this question upstream to the Zotero team https://github.com/zotero/zotero/issues. Dan, can I ask you to draft a ticket that explains Ben's use case, and then summarizes how Zotero's parser is getting confused by the nesting? And if you have ideas about how Zotero could work around this at the API level, that'd be great - maybe something like a HTML5 data attribute on certain elements that marks them as ignored by Zotero? Maybe provide a link to the problematic page so that the Zotero team can see what we're talking about. Then maybe Ben could read it over (at least the first part) to make sure we've captured the use case properly, before it gets submitted.
Updated by Daniel Jones almost 12 years ago
Sounds good - just to be clear the question I'm posing is around adding support for turning off certain translators, right?
Also - I dug a little bit more and found our how Zotero establishes priority between different translators. There's a number in the translator's js file that indicates priority, and the lower it is, the greater priority is given. DOI's translator is set to 300, and COinS is set to 250, so if the COinS plugin is being used, it should be taking priority. So I'm guessing that the JITP site isn't using the COinS plugin or it'd be finding that first.
Here's a draft for the ticket -
Title: "Adding ability for web pages to turn off specified translators"
Content:
"It would be good to be able to signal to Zotero not use certain translators on a given web page. For example, we have an online journal where the articles' bibliographies sometimes list DOIs in their entries. However, we don't want Zotero to automatically parse those DOIs and give the option to save them to the Zotero library, as that could conflict with metadata about the article itself we're trying to expose to Zotero. You can see an example at http://jitp.commons.gc.cuny.edu/city-of-lit-collaborative-research-in-literature-and-new-media/. Would there be a way, maybe through an HTML5 data attribute on some element, to let Zotero know not to use certain translators on the page?"
Does that sound right?
Updated by Ben Miller almost 12 years ago
Thanks, Dan -- this is really useful to know. What I take away from this is that we really just need to activate the COinS plugin and use it, because that ought to take care of the problem altogether. That is: in any situation in which there's "metadata about the article itself we're trying to expose to Zotero," the COinS translator should get there first, thereby avoiding any conflict. Right?
If that works, then we don't need to post the issue to Zotero after all, and they don't have to go to the trouble of making every translator check for a new data attribute before launching.
If we try the COinS plugin and there's still a conflict, then we'll know we need to dig deeper, and we'll have a more confounding issue to present to them.
I can test on the jitpstaging site and report back.
Updated by Ben Miller almost 12 years ago
Hmm, well, the COinS translator picks up as it ought to, but now JITP has another problem: our mechanism for posting the articles without giving every author a unique account on the Commons means that the exposed metadata treats every article as posted by our Managing Editor. Neither of the CHNM COinS exposers let you customize the values of the fields: it's just post author, post title, etc.
On the plus side, it means the bug as initially reported is more or less fixed.
On the down side, we at JITP will need to do a little more work to get the proper metadata in there.
Luckily, Zotero can generate COinS, as explained here: https://www.zotero.org/support/dev/exposing_metadata/coins/. Using this technique, I was able to manually create a Zotero entry for the 'City of Lit' article, change my citation style to COinS, drag it into the html editor of the post, and successfully generate a one-click citation. (The snapshot it grabbed was just the login page, but presumably that would work properly on the live site, which isn't behind a password.)
So I'm thinking I should now move this over to the JITP's internal discussion board. Yes?
Updated by Ben Miller almost 12 years ago
To clarify, for the record: I had to turn off the COinS plugins, and insert the COinS span generated by Zotero into the text editor, to get the translator to find the correct metadata.
Updated by Boone Gorges almost 12 years ago
our mechanism for posting the articles without giving every author a unique account on the Commons means that the exposed metadata treats every article as posted by our Managing Editor. Neither of the CHNM COinS exposers let you customize the values of the fields: it's just post author, post title, etc.
Thanks, Ben. To this extent, it sounds like the JITP setup is unusual. Though I do think it's a worthwhile feature request to the COinS plugin to allow overriding the post author (or other information) with custom info. I see that the COinS plugins available on the Commons are very bare bones in this respect. Dan, you mind taking a look at the other WP plugins listed on https://www.zotero.org/support/plugins to see if any of them have this kind of feature? It's something we could build fairly easily (either as a new plugin, or an add-on to a CHNM-supported plugin) if we thought it was a high priority for the Commons.
Regarding the Zotero upstream request: I still think there's room for an enhancement here (or at least a support request - maybe there's something we're missing). Dan, your draft looks pretty good to me - maybe you could frame it a little more in the form of a question, because I guess there may already be a way to do what we're asking. But other than that, please do go ahead and submit it. Thanks!
Updated by Daniel Jones almost 12 years ago
So I don't know how high of a priority this is but I did make the request on Zotero's github page. I also looked at the other plugins they have listed - there's only one that looks like it allows for entering custom data for the COinS span - https://www.wallandbinkley.com/quaedam/2005/08_09_coins-wordpress-plugin-update.html but it hasn't been updated in a long time and doesn't seem to work anymore. Could be a good jumping off point though for our own plugin. It doesn't include anything for author right now but it'd be easy to add. Looks like it's trying to add a button to the post editor but was written so long ago it doesn't work anymore.
Let me know if there's more work you want me to do on this for now.
Updated by Matt Gold almost 12 years ago
Thanks, Daniel. For our ticket records, can you please share a link to the github issue? Thanks.
Updated by Daniel Jones almost 12 years ago
Sure thing! https://github.com/zotero/zotero/issues/530
Updated by Boone Gorges almost 12 years ago
- Target version changed from Not tracked to Future release
Thanks, Daniel!
Sorry for suggesting you post on the Github tracker - didn't mean for you to get scolded there ;)
It seems like aurimasv has a good suggestion regarding building our own translator, but that seems like it's way overkill for our purposes.
Given that Ben has figured out a workaround for the current problem, I'm going to put this ticket in Future Release, so we can consider the possibility of building an improved COinS plugin.
Updated by Daniel Jones over 11 years ago
Just wanted to check if there's anything else I ought to do on this right now - do we want to start work on improving the COinS plugin?
Updated by Boone Gorges over 11 years ago
Hi Dan - Thanks for following up. Matt can chime in here, but I'd say let's hold off for now on doing significant work on the COinS plugin. If you'd like to spend a few minutes fleshing out your "doesn't seem to work anymore" observation and posting your findings here, we can think about next steps. If there's something very simple that needs to be done to restore basic functionality, let's do it, but it seems like a relatively low priority otherwise.
Updated by Matt Gold over 11 years ago
I agree with Boone's assessment here and I look forward to your thoughts, Dan.
Updated by Daniel Jones over 11 years ago
So the way this plugin was written, a number of years ago, used some javascript to manually append a new button to the toolbar and to handle creating the form and handling form submission for custom COinS data. I think Wordpress now has filters and actions to handle adding TinyMCE buttons. Looks like we'd have to write a totally new plugin.
Is this high enough priority that I should work on it?
Updated by Matt Gold over 11 years ago
Thanks, Dan. I think we should hold off for now, though we might point out the issue to the Zotero team. Perhaps we could let them know what we've found and let them take it from here?
Updated by Daniel Jones over 11 years ago
Okay sounds good - we brought this up with them a little while ago and they more or less said they were working on something else already that will eventually solve this problem, and basically passed it back to us to find our own solution for our particular use-case.
Updated by Boone Gorges over 9 years ago
Dan and/or Ben, is this still an issue on JITP now that ScholarPress COinS allows for custom metadata?
Updated by Ben Miller over 9 years ago
Yes and no – though the "yes" will, I think, be enough to close this ticket. But I'm afraid the "no" may re-open the other one.
The yes: Testing on http://jitpstaging.commons.gc.cuny.edu/city-of-lit-collaborative-research-in-literature-and-new-media/, I can confirm that the ScholarPress COinS translator kick in as planned, and Zotero grabs whatever data is in the custom fields assigned by it. Thanks, Dan, for all your hard work on that plugin!
The no: Unless I'm missing a way to trigger it, the plugin currently only allows for one author, with a single clear "last name" field. In the case of multiple authors, I tried a workaround of treating only the first author's last name as the requested "last name," and putting all other authors in the "first name" field, just to see what Zotero would do with it. Perhaps unsurprisingly, it treats this as a single author with a simple last name and a really complicated first name.
Don't get me wrong: it's still a vast improvement, and I'm grateful for it, and in many citation styles it'll probably even look right. But if there could be some way to make "author" an array, that would probably be better still.
I'll cross-post this to https://redmine.gc.cuny.edu/issues/5490.
Updated by Boone Gorges over 9 years ago
- Status changed from Assigned to Duplicate
- Target version deleted (
Future release)
Thank you so much for the detailed and quick follow-up, Ben! I'm going to close this one.